
![]()
Klik vervolgens met je rechter muisknop op een van de meetpunten en kies "trendlijn toevoegen". Kies onder type: lineair en vink aan onder opties: vergelijking in grafiek weergeven en R-kwadraat in grafiek weergeven.
De regressiecoëfficient geeft aan hoe goed de punten op de rechte lijn vallen. Voor beide apparaten vallen de gemeten punten zeer goed op de lijn, de fouten zijn dus zeer klein. De regressiecoëfficient geeft echter geen informatie over hoe de fouten verdeeld zijn. Hierdoor is het mogelijk dat bij 1 of beide meetreeksen de beste lijn niet een lineaire is, maar dat een kromme lijn beter door de punten loopt. Oftewel dat het verband niet lineair, is maar dat een krom verband geldt.
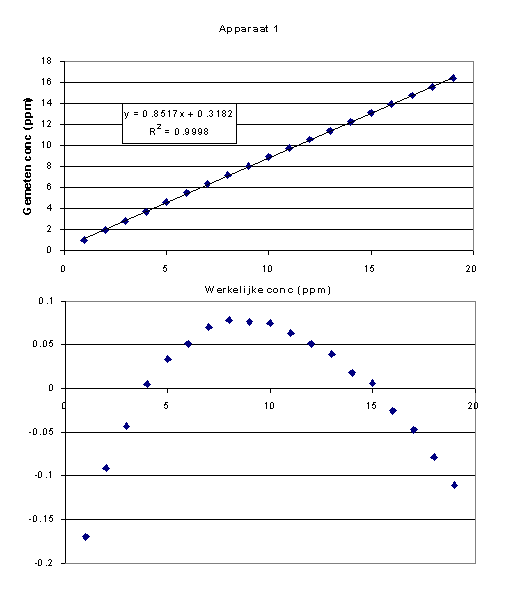

De beste lijn door de punten blijkt dan ook y=x0,95 te zijn.Apparaat 2:
Voor de Standaard-additie methode wordt de fout door extrapolatie echter snel groter, aanvullend onderzoek zou nodig zijn om deze fout te bepalen.
Aan de hand van deze uitkomsten kan je wel een redelijke schatting maken wat deze fout zal zijn. Als namelijk alleen de punten vanaf 8 genomen wordt om de lijn mee te trekken (dus alsof er in het monster 7 ppm zit en er 11 standaard-addities van 1 ppm worden toegevoegd, de lijn die dan gevonden wordt: y = 0,8345x + 0,5629), en vervolgens berekend wordt wat het snijpunt met de x-as is blijkt dit -0,674536 te zijn. Aangezien gerekend is alsof in het monster 7 ppm aanwezig is betekent dit een fout van: 0,674536/7*100%= 9,64%. Dus deze lijn, die op het oog zeer goed lineair en precies lijkt te zijn, is niet bruibaar voor een gehaltebepaling via de standaard-additiemethode.Apparaat 2:
Vraag 2

Klik vervolgens met je rechter muisknop op een van de meetpunten en kies "trendlijn toevoegen". Kies onder type: lineair en vink aan onder opties: vergelijking in grafiek weergeven en R-kwadraat in grafiek weergeven.
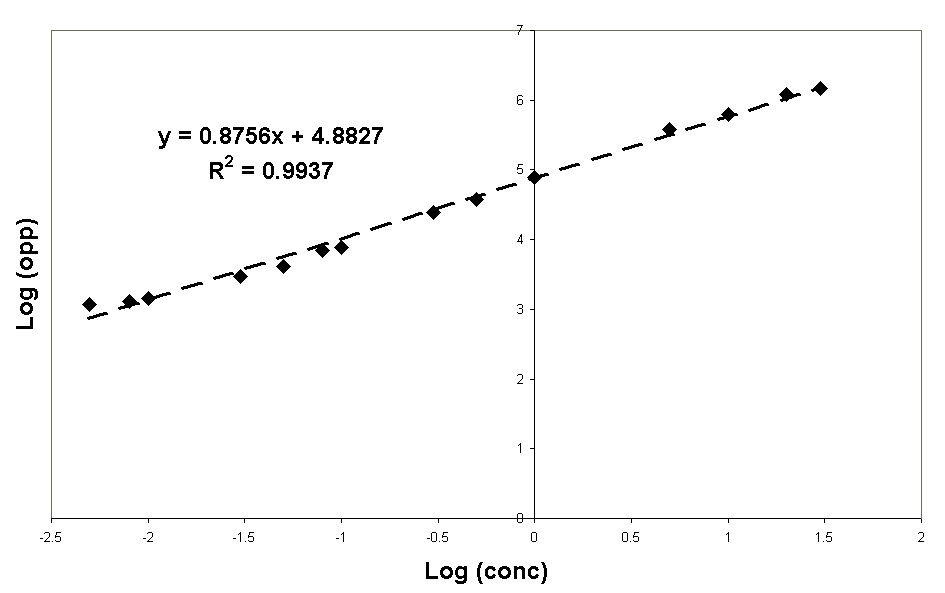
Om ook de lagere concentraties beter te beoordelen wordt een log/log-plot gemaakt. bereken met behulp van de log-functie de logaritmische waardes uit en zet deze op dezelfde manier als bij b uit in een grafiek.
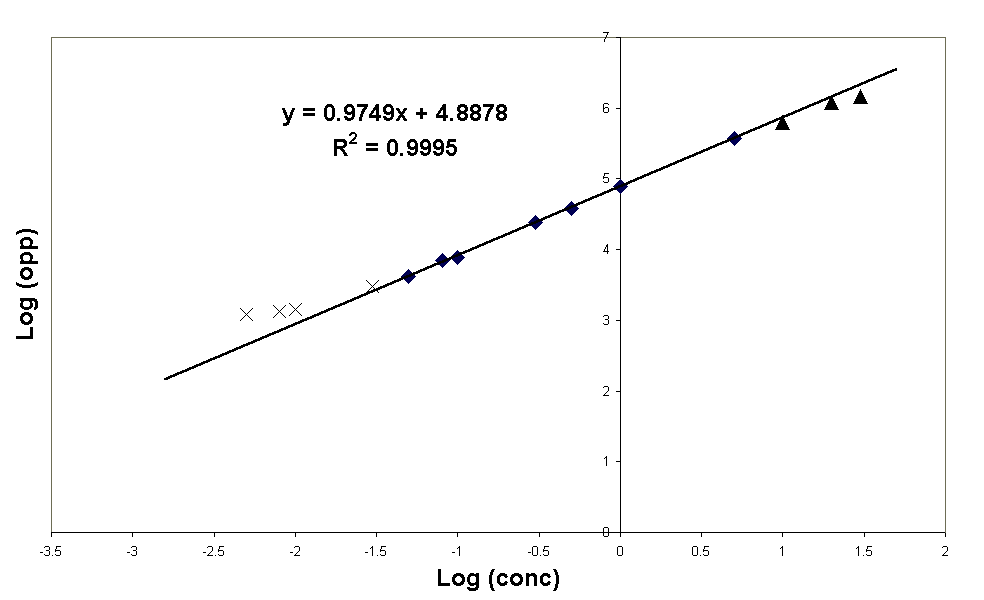
tweede gedeelte levert een beste rechte lijn op van:
Let op! Een rechte lijn in een log/log-plot betekent niet automatisch een rechte lijn in een normaal assenstelsel. De richtingscoefficient in het log/log-plot is de macht van de lijn. Een rechte lijn met RC=2 in het log/log-plot levert een kwadratische (y=~x2) functie in een normaal assenstelsel.
Aangezien in een log/log-plot de RC (0,9749) van de lijn de macht van de lijn in een lineair assenstelsel is, betekent dit dat de regressielijn vrijwel een perfect lineair verband zal vertonen (als de macht van een functie exact 1,0000 is er sprake van een perfect rechte lijn)
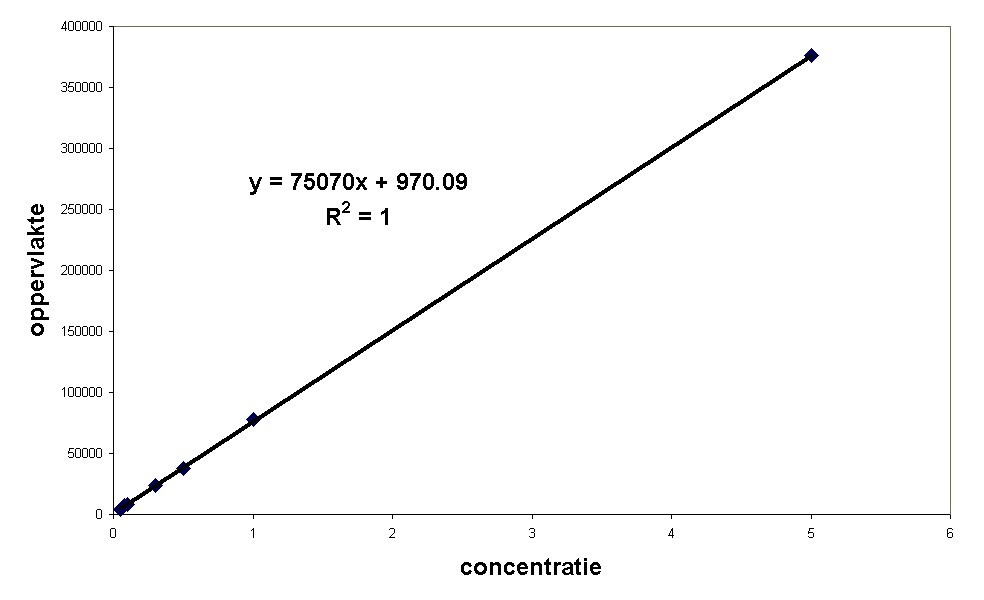
Als nu alleen de punten van het interval 0,05 t/m 5 genomen worden om de regressielijn mee te bereken levert dit de volgende lijn op:
Uit de R-kwadraat = 1 volgt dus ook dat er zeer weinig (absolute)spreiding aanwezig is.
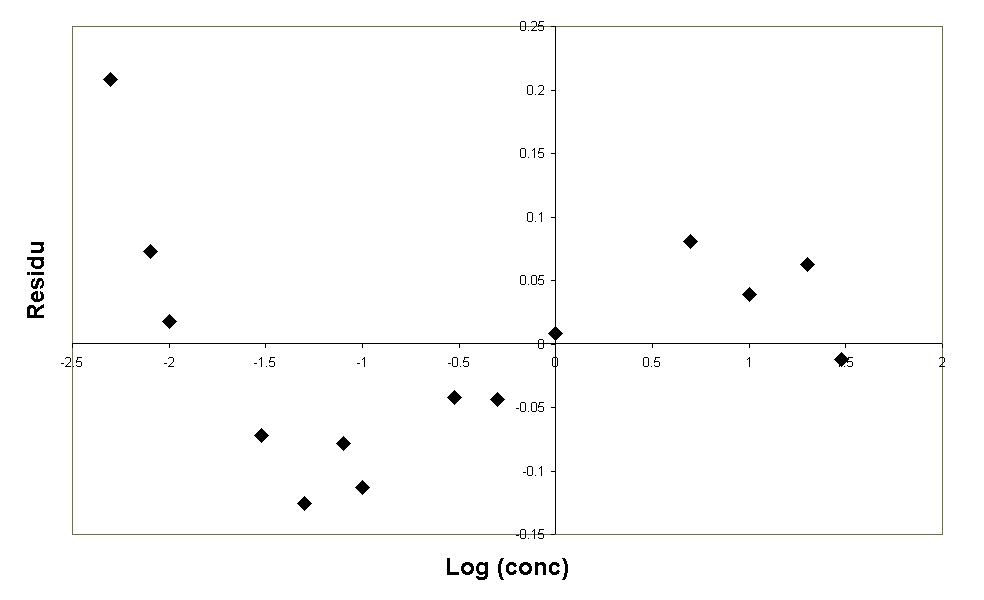
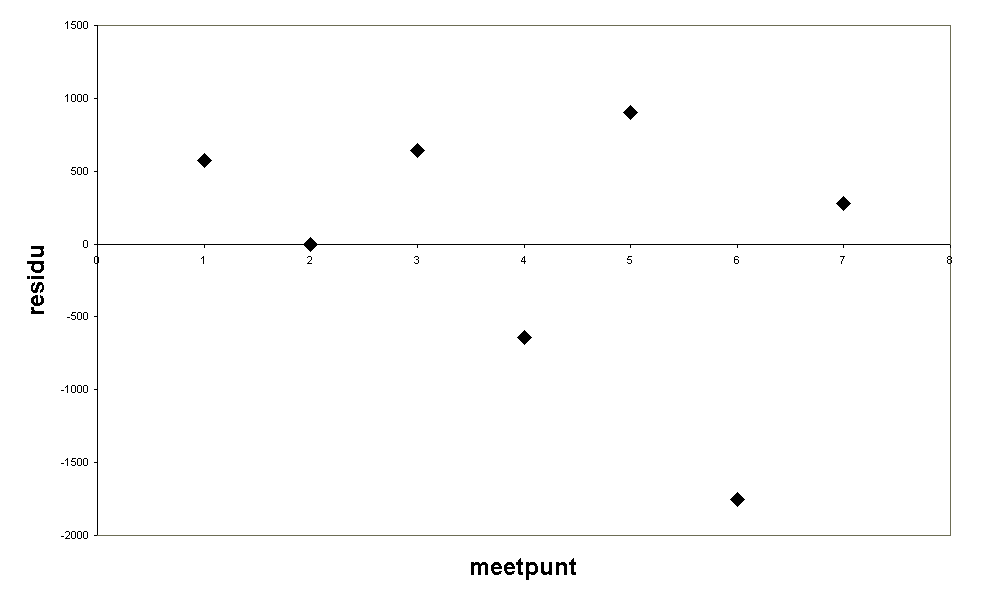 De residuen vertonen geen trend, dus de metingen lijken lineair binnen dit gebied. (let op, op de x-as staat niet de concentratie, maar gewoon het nummer van de meting, zo wordt alles gelijkmatig verdeeld over de as en worden de lagere concentraties niet zo op elkaar gedrukt waardoor de residuen moeilijker te beoordelen zouden zijn).
De residuen vertonen geen trend, dus de metingen lijken lineair binnen dit gebied. (let op, op de x-as staat niet de concentratie, maar gewoon het nummer van de meting, zo wordt alles gelijkmatig verdeeld over de as en worden de lagere concentraties niet zo op elkaar gedrukt waardoor de residuen moeilijker te beoordelen zouden zijn).
Als er gekozen wordt om inderdaad een hogere standaard eerst in te spuiten om de plaats van de piek te bepalen, moet altijd van te voren een blanco opgenomen worden om te bewijzen dat er niets in het apparaat zit dat stoort, vervolgens moet na de meting ook weer een blanco opgenomen worden om te bewijzen dat niets van de voorgaande injectie is overgebleven. Dit kan echter zoveel problemen opleveren dat er ook in overweging genomen kan worden om gewoon te gaan injecteren zonder eerst de plaats van de piek te bepalen. Bij de hogere concentraties komt deze vanzelf naar voren.
Laatste opmerking: Voor degene die er niet in geslaagd is om de grafieken in excel te maken, is deze excel-file bij vraag 2 aanwezig om down te loaden. Hierin zijn alle grafieken opgenomen, zodat gezien kan worden hoe deze gemaakt zijn. Probeer echter eerst zonder deze file zelf de grafieken te maken!
|
Dag |
voorspelde y |
residuen |
Dag |
voorspelde y |
residuen |
|
1 |
36,7 |
-2,7 |
7 |
36,7 |
0,3 |
|
2 |
28,2 |
1,8 |
8 |
43,8 |
2,2 |
|
3 |
51,1 |
-0,1 |
9 |
47,6 |
0,4 |
|
4 |
31,0 |
-1,0 |
10 |
37,1 |
0,9 |
|
5 |
34,0 |
-1,0 |
11 |
49,0 |
-1,0 |
|
6 |
37,7 |
0,3 |
|
|
|
De standaard fout in de helling is dus 0,00746. De 95% betrouwbaarheidsinterval is:
b � t(n-2); 0,025 * SE = 0,120 � 2,26 * 0,00746 = 0,120 � 0,017
Vraag 4
y = a+ b*x � t5; 0,025 * syx * Ö (1/7 + (440 � 341,3)2/ 11179,43)
y = 35,12 � 2,8
Er wordt aangenomen dat de curve ook bij deze (geëxtrapoleerde) waarde hetzelfde verband vertoond.
y = a+ b*x � t5; 0,025 * syx * S (1/7 + (440 � 341,3)211179,43 + 1)
y = 35,12 � 4,0
De precisie van de thermometer is de af te lezen aan het onverklaarde gedeelte in de R2. Ook de syx zegt iets over de spreiding van de punten ten opzichte van de regressielijn, evenals de grafiek van de residuen in y, tegen de x-waarden.
|
temperatuur |
voorspelde y |
residuen |
temperatuur |
voorspelde y |
residuen |
|
20,0 |
20,5 |
-0,091 |
100,0 |
100,1 |
0,089 |
|
50,0 |
50,3 |
-0,149 |
102,0 |
102,1 |
-0,001 |
|
80,0 |
80,2 |
0,794 |
105,0 |
105,1 |
0,013 |
|
90,0 |
90,2 |
0,042 |
115,0 |
115,0 |
-0,339 |
|
95,0 |
95,1 |
-0,435 |
121,0 |
121,0 |
0,189 |
|
98,0 |
98,1 |
-0,120 |
125,0 |
125,0 |
0,008 |
syx = 0,320
b = 0,995 � 2,23 * 0,00321 = 0,995 � 0,007
De werkelijke helling van de lijn ligt met 95% betrouwbaarheid tussen de 0,988 en 1,002.
H0 : b = 1; H1 : b � 1
tberekend = 0,995 - 1 / SE = 0,005 / 0,00321 = 1,56; t9; 0,025 = 2,23
Met een foutkans van 5% kan de H0 (dat de thermometer juist is) niet worden verworpen. (er treedt geen proportionele fout op)
Verder mag het intercept niet afwijken van 0. Dit kan op dezelfde manier bewezen worden als bij vraag 1e, waarbij x0=0. Als nu y=0 binnen het gevonden betrouwbaarheidsinterval ligt, kan met een foutkans van 5% de H0 niet verworpen worden (er treedt ook geen constante fout op).aangegeven temperatuur = 100,1 � 0,7 graden
Dit is een strikvraag: voor elke afzonderlijke meting is de voorspellingsinterval natuurlijk even groot. Het gemiddelde van al deze metingen, heeft wel ander interval. Dit is kleiner, omdat de term +1 (uit vergelijking in opgave 2e) dan wegvalt en de vergelijking uit opgave 2d gebruikt kan worden.
2 Februari 2000
Staf Farmaceutische Analyse 5e-jaar