
![]()
De leerstof voor het cursusonderdeel Validatie omvatten het volgende:
Met deze oefenopgaven wordt de student gesteund in het bestuderen van de leerstof. Er wordt met de oefenopgaven aandacht besteed aan:
Bestudeer voor het werkcollege stastistiek de onderstaande passages uit het dictaat Wiskunde en Statistiek. Centrum voor Biostatistiek. Utrecht. Dit is het dictaat gebruikt bij de cursus statistiek in de propadeuse. Indien u tijdens deze cursus gebruik heeft gemaakt van het het boek (Miller & Miller. Statistics in analytical chemistry, 3e editie) wordt aangeraden deze als leidraad aan te houden
De paginanummering is gebaseerd op het dictaat uit 1995. Bij de andere uitgaven kunnen de nummers niet volledig overeenkomen. Er kan dan op de titels van de paragrafen worden gezocht.
t-toets
pagina 53 t/m 63 met uitzondering van voorbeeld 1 en voorbeeld 2; pagina 73 vanaf 'toets gebaseerd op normale verdeling met bekende m' t/m pagina 76 'gepaarde waarneming'; pagina 81 't-toets voor twee steekproeven'.
voor Miller & Miller: pagina 53 t/m 60, hoofdstuk 3.1 t/m 3.5
Q-toets
Dit onderdeel staat niet vermeld in het dictaat. Een korte uitleg over de theorie volgt verderop.
voor Miller & Miller: pagina 62 t/m 65, hoofdstuk 3.7
F-toets
pagina 82 t/m 83 tot '2-steekproeven voor Wilcoxon'
voor Miller & Miller: pagina 60 e.v., hoofdstuk 3.6
regressielijn
pagina 26 t/m 30
voor Miller & Miller: pagina 102 t/m 113, hoofdstuk 5.2, 5.3, 5.5 en 5.6
Bestudeer ook de samenvatting op pagina 98.
Opgaven voor werkcollege
De te bestuderen stof kan worden geoefend met behulp van de oefenopgaven. Hiervan is een exemplaar te raadplegen via internet Oefenopgaven statistiek. Bij de practicumstaf is een papieren exemplaar van deze opgaven beschikbaar om te kopi�ren.
Tijdens het werkcollege statistiek zal aan de hand van voorbeelden de leerstof kort worden toegelicht. Na afloop van het werkcollege is er tijd om de paragrafen uit het boek of het dictaat door te nemen en zelfstandig of in groepen met enkele extra opdrachten de statistiek weer op te halen.
Tijdens het college validatie wordt tevens ingegaan op de lineaire regressie. Er wordt verwacht dat voor aanvang vraag 1 t/m 3 van de lineaire regressie zijn gemaakt.
Dixon Q-toets
Het doel van de toets is een statistisch correcte uitspraak te doen of een waarneming uit een meetreeks afwijkt van de rest van de meetwaarden. Zo'n meetwaarde wordt ook wel een uitbijter genoemd.
De uitvoering van de Q-toets is het volgende: plaats eerst alle waarnemingen op volgorde van grootte. Bereken de toetsgrootheid Q met:
Q = | afwijkende waarde - dichtsbijgelegen waarde| / ( hoogste waarde - laagste waarde)
De uitkomst van de berekening (Qberekend) wordt vergeleken met de tabelwaarde. Is de berekende waarde groter dan de tabel waarde, dan kan met de gekozen zekerheid (1 - a) geconcludeerd worden dat de afwijkende waarde een uitbijter is. Deze hoeft dan niet meegenomen te worden in de verdere statistische berekeningen.
Bij de Q-toets zijn wel enkele kanttekeningen te plaatsen. Bedenk altijd dat de Q-toets een uitspraak doet over de waarschijnlijkheid dat de afwijkende waarde een uitbijter is. Er is dus altijd de mogelijkheid op een vals positieve of vals negatieve conclusie. Verder kan de toets niet worden toegepast als er twee of meer afwijkende meetwaarden in de meetreeks zijn. Daar zijn weer andere toetsen voor, maar deze vallen buiten het bestek van de cursus. Als laatste opmerking moet worden vermeld dat de toetsgrootheid alleen kan worden gebruikt als het aantal waarnemingen (n) kleiner is dan 8.
Korte aanvullende theorie voor de berekening van betrouwbaarheidsintervallen (zie ook Miller & Miller, pagina 41 e.v., hoofdstuk 2.4)
Omdat in bijna alle gevallen binnen de farmaceutische analyse het werkelijk gehalte of de werkelijke spreiding niet bekend zijn, zal er veel worden gerekend met 'zuivere schatters' van deze m en s. Dit zijn de xgemiddeld en de s2. Om toch een aanwijzing over de werkelijke waarde te kunnen geven is het gebruikelijk om bij elke waarneming het betrouwbaarheidsinterval (BI) mee te geven. Er kan dan met een bepaalde zekerheid (1-a) worden gesteld, dat het BI de werkelijke waarde omvat. Anders gezegd: alle waarden binnen de grenswaarden van het interval mogen worden beschouwd als een mogelijke waarde voor het werkelijke gemiddelde. Voor de gemiddelde van een waarneming kan deze worden bepaald met behulp van de volgende vergelijking:
vergelijking 1: betrouwbaarheidsinterval van het gemiddelde![]()
- m het werkelijke gemiddelde,
- x het berekende gemiddelde,
- s de berekende standaarddeviatie (de wortel uit de steekproefvariantie),
- n het aantal waarnemingen waarop x en s zijn bepaald,
- de factor t is een constante, die afhangt van de onbetrouwbaarheid awaarbij de uitspraak wordt gedaan. De n-1 staat voor het aantal vrijheidsgraden (n-1) wat deze constante heeft. Deze tn-1; a is op te zoeken in diverse statistische tabellen.
Toelichting bij a en b-fouten:
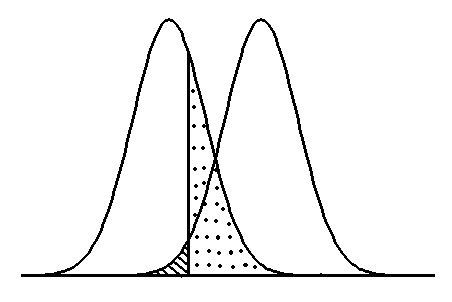
In de onderstaande figuur is te zien wat het verband is tussen
De enige manier beide om fouten kleiner te maken, is door het vergroten van de steekproef. Daarmee nemen de varianties af en worden de curves smaller. Er zal nu dus minder overlap zijn. Teken deze situatie voor jezelf na.
Omdat de alternatieve hypothese nooit één waarde is, maar altijd >, < of ¹
aan een bepaalde waarde, zijn er oneindig veel mogelijke curves voor de alternatieve hypothese op te stellen. Bij een vast waarde van a hoort daarom ook een hele reeks waarden van b. De b-fout is dus niet zomaar uit te rekenen. Wordt er in een toets daarom een waarde gevonden die niet in het gebied a ligt, is er geen uitspraak te doen over de grootte van de kans dat de waarde in gebied b ligt. Er kan dus geen conclusie worden getrokken of de nulhypothese waar is. Om die reden wordt als ttabel > tberekend de conclusie dat de nulhypothese niet is te verwerpen. De conclusie dat de nulhypothese waar is, is vanwege de vele mogelijke waarden van b, niet te bewijzen.
figuur 1: Curves van de verdeling van x (bijvoorbeeld gemeten gehaltes), onder de aanname dat H0 waar (rechter curve) of dat H1 waar (linker curve) is. Het gearceerde gebied is
Toelichting bij de toetsingsprocedure
De toetsen van hypotheses omvat een aantal stappen. Ter verduidelijk zijn deze stappen achter elkaar gezet. Dit stappenplan geeft een handreiking om een hypothese op een juiste en volledige manier te toetsen. Er is geen verplichting om hypothesetoetsen op deze manier uit te voeren, maar als de procedure word gevolgd is er geen risico dat er essentiele informatie over het hoofd wordt gezien.
Voor er wordt gemeten worden eerst de volgende stappen uitgevoerd.
Na de meting wordt gekeken of de meetreeks uitbijters bevat. Daarna worden de volgende stappen uitgevoerd:
(bijvoorbeeld: Verschilt het gemiddeld gehalte significant van 100,0%: H0: m = 100,0% H1: m ¹ 100,0%)
(In het bovenstaande voorbeeld dus: standaard t-toets: (m - xgem) / (s / Ö
n))
(a
is bijvoorbeeld 0,05)
= F6;4; 0,05 = ...).
(bijvoorbeeld: tdf; 1/2a = t7; 0,025 = ... of Fdf1;df2; a
8 september 1999
Staf Farmaceutische Analyse 5e-jaar