

Farmaceutische Analyse
Antwoorden Vraagstukken Hypothese toetsen
laatst bijgewerkt op: 25-06-2001
Vraag 1
Stap 1: Formuleer de vraagstelling, zowel in woorden als statistisch
Bepaal of het gevonden gemiddelde gehalte zwavel in het monster significant afwijkt (alfa=0.05) van de gedeclareerde waarde van 0.326%.
H0: Xgem= 0.326%
H1: Xgem <>0.326%
Stap 2: Kies de juiste toetsgrootheid, afhankelijk van de vraagstelling die is geformuleerd.
(Xgem - 0,326) / (s/wortel(n))
Stap 3: Kies de gewenste onbetrouwbaarheid (alfa ). Bedenk of je de hypothese eenzijdig of tweezijdig wilt toetsen.
Alfa is hier gesteld op 0,05.
Aangezien er geen rede is om enkelzijdig te toetsen, moet er dus dubbelzijdig getoets worden.
Stap 4: het uitvoeren van de berekeningen
Na de meting wordt gekeken of de meetreeks uitbijters bevat:
(0.360-0.332)/(0.360-0.314)= 0.609
Q-tabel 9; 0.05= 0.564
Dus de waarde 0.360 is een uitbijter, deze wordt verder niet meegenomen in de berekening.
Vervolgens wordt het gemiddelde en de standaarddeviatie berekend
Xgem= 0.324
Sd= 0.007126
Na invullen in de formule levert dit de volgende t-waarde: 0.893
Stap 5.Vergelijk met de tabelwaarde en noteer ook welke tabelwaarde is genomen, onder vermelding van de a en het aantal vrijheidsgraden.
De tabelwaarde voor t 7; 0.05=2.36
De berekende waarde is kleiner dan de tabelwaarde.
Met 95% betrouwbaarheid kan de hypothese, dat het gemiddelde gehalte zwavel 0.326% is, niet worden verworpen.
Vraag 2
-
AB: Fberekend = 9,81; F5;4; 0,05 = 9,36
Met een foutkans van 5% kan geconcludeerd worden dat H0 (de aanname dat de varianties van de de coulometrische en de titratie gelijk zijn) kan worden verworpen.
De varianties behoren niet bij dezelfde populatie. Er wordt tweezijdig getoets, er kan niet van te voren worden beredeneerd welke methode het meest nauwkeurig zal zijn.
AC: Fberekend = 1,14; F3; 4; 0,05 = 9,98
BC: Fberekend = 8,57; F5; 3; 0,05 = 14,9
-
AC: Sp=0,1393; tberekend = 4,93; t7; 0,05 = 2,36
Met een foutkans van 5% kan worden geconcludeerd dat de H0
(de aanname dat de uitkomsten van de coulometrische en gravimetrische analyse
gelijk zijn) mag worden verworpen. De uitkomsten verschillen dus significant
van elkaar (bij alfa = 0,05).
BC: tberekend = 0,563 t8; 0,05 = 2,31
AB: Aangezien de varianties significant verschillen is een ongepaarde t-test
met gepoolde variantie niet mogelijk. Volgens de onderstaande vergelijking
kan de t-waarde worden uitgerekend:
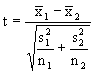
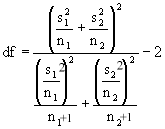
Het aantal vrijheidsgraden wordt dus kleiner en de ttabel
dus groter. Met andere woorden; wil er met dezelfde betrouwbaarheid kunnen worden
aangetoond dat de H0 moet worden verworpen, dan moet het verschil
in de gemiddelden nog duidelijker (= groter) zijn dan bij metingen met een gelijke variantie.
Vraag 3
-
m = 498,4 ± 3,2, de waarde 500,0 valt binnen dit betrouwbaarheidsinterval. Het gemiddelde van de steekproef wijkt dus niet significant af van de gedeclareerde waarde.
Via de standaard t-toets kan men tot dezelfde conclusie komen: Tberekend: 1,19; T(7, 0,05): 2,36. De berekende t-waarde is kleiner dan de kritieke waarde, dus het gemiddelde van de meetreeks wijkt niet significant af van de gedeclareerde waarde. De "nette"manier van formuleren is als volgt:
Met 5% foutkans is de H0 (de aanname dat het gemeten gemiddelde gehalte gelijk is
aan gedeclareerd gehalte) niet te verwerpen.
-
m = 497,3 ± 2,09 * 0,492 = 497,3 ±1,0
Via de standaard t-toets: tberekend=5,48; t(19,0,05)=2,09
De H0 is te verwerpen.
De H1 (dat het gemeten
gemiddelde gehalte significant afwijkt van het gedeclareerd gehalte) is dus, met 5% foutkans, correct.
-
Fberekend = 3,02; F7;19;0,05 = 3,07 (interpoleren
tussen 15 en 20)
Met 5% foutenkans is de H0 (de aanname dat de varianties gelijk), niet te verwerpen.
tberekend = 0,951; t26;0,05 = 2,06
Met 5% foutkans is de H0 (dat de beide xgem gelijk
zijn) niet te verwerpen.
-
Fberekend = 1,42; F5;5; 0,05 = 7,15
Met 5% foutenkans is de H0 (de aanname dat de varianties gelijk), niet te verwerpen.
tberekend = 2,57; t10; 0,05 = 2,23
De H0 is te verwerpen. De H1 (de aanname dat de xgem van beide methoden significant verschillen) is dus, met 5% foutkans, correct.
-
tberekend = 2,41; t5; 0,05 = 2,57
Met 5% foutenkans is de H0 (de aanname dat de gemiddelde verschillen van de batches
gelijk zijn), niet te verwerpen.
Opmerking bij vraag 3d.
Op waarnemingen m.b.v. verschillende, onafhankelijke methoden van eenzelfde
monster, kan het beste ongepaard worden getoetst. Hierbij worden
m 1 en m
2 vergeleken. De xgem is een betere schatter van de ware waarde m dan de afzonderlijke meetwaarden. Het betrouwbaarheidsinterval is dus kleiner en de t-toets is eerder significant verschillend. Voorbeeld: Er wordt een grote pot koffie gezet en er wordt met verschillende methodes het gehalte aan coffeine bepaald. De spreiding in de meetresultaten wordt alleen veroorzaakt door de meetmethode, niet door het monster (dat is immers steeds dezelfde homogeen verdeelde "coffeine-oplossing". Hoe meer metingen hoe beter deze spreiding wordt weggemiddeld (standaarddeviatie gaat met een factor wortel(n) omlaag.
Opmerking bij vraag 3e.
Op 2 �afhankelijke� reeksen van waarnemingen m.b.v. verschillende methode op verschillende monsters kan het beste gepaard worden getoetst. Het verschil tussen de afzonderlijke monsters in de twee reeksen wordt uitsluitend veroorzaakt door de verschillen in de methode. Bij ongepaard toetsen verliest men de informatie
over m , doordat de spreiding rond xgem wordt beïnvloed door spreiding in de methode en door spreiding in de meetreeks ! Voorbeeld: het gehalte coffeïne in een kopje koffie gezet van verschillende merken, dat op 2 manieren wordt bepaald. De 2 methodes zouden per merk (= hetzelfde monster) hetzelfde resultaat op moeten leveren (= �afhankelijke� waarnemingen). De spreiding wordt alleen bepaald door de analysemethode. Zou nu het gehalte coffeïne van alle merken worden gemiddeld en op deze manier de 2 methode vergelijken, dan is in het antwoord niet alleen de spreiding in de analyse, maar ook de spreiding in het merk opgenomen. Als echter per meetpaar alleen het verschil tussen de metingen wordt bekeken wordt de spreiding in het monster niet meer meegenomen, en kan dus nauwkeuriger een uitspraak worden gedaan over de methode's.
Tenslotte, waarnemingen m.b.v. verschillende, onafhankelijke methoden op verschillende, onafhankelijke
monsters kan ook het beste ongepaard worden getoetst. Echter, m
is nu moeilijker te schatten met xgem omdat de betrouwbaarheidsinterval
wordt bepaald door de spreiding in de methode en door de spreiding in de monsters. Gepaard toetsen is niet mogelijk, omdat daar de aanname geldt, dat er geen spreiding in het monster is. Voorbeeld: Er wordt met twee verschillende methode's het gehalte aan coffeine in steeds opnieuw gezette kopjes koffie bepaald (deze hebben dus een variabel gehalte aan coffeine). Omdat met deze opzet nooit over het monster of over de methode's apart een uitspraak kan worden gedaan, maar men altijd een uitspraak doet over de spreiding van de methode's en de spreiding monsters gezamelijk, levert deze proefopzet vaak geen bruikbare gegevens op.
Vraag 4
-
analist 1: tberekend = 0,536; t4;0,05 = 2,78
analist 2: tberekend = 0,047; t3;0,05
= 3,18
Dus de gemiddelde gevonden waarde van beide analisten wijkt niet significant af van de ware waarde. (of netter gezegd: er kan niet met 95% zekerheid gezegd worden dat de gevonden waardes significant afwijken van de ware waarde).
-
Fberekend = 1,025; F4;3;0,05 = 15,1
-
tberekend = 0,394; t7;0,025 = 2,36
Met 5% foutkans is H0 (dat de twee analisten hetzelfde gemiddelde vinden) niet
te verwerpen.
(opmerking: in deze vraag is op drie manieren dezelfde conclusie verwoord, namelijk dat de berekende t-waarde niet groter is dan de kritieke t-waarde, de statistische betekenis is echter hetzelfde)
Vraag 5
-
H0: xgem = 0,500 H1: xgem ¹
0,500
tberekend = (0,499 - 0,500) / SE = 0,31; t7; 0,01
= 3,50
Met een foutkans van 1% kan de H0 (de aanname dat de concentratie
inactieve stof 0,500 mg/ml bedraagt) niet worden verworpen.
NB: Om hieruit te concluderen dat de methode juist is, is statistisch gezien niet helemaal verantwoord. Met een andere foutkans zou de uitspraak wellicht wel kunnen worden verworpen. (Eén meting is een uitbijter).
-
Omdat het hier slechts metingen onder zo min mogelijk variaties betreft, kan alleen iets over de herhaalbaarheid worden gezegd. De RSD = 2,3%
-
Bij verandering van de waarden zal het gemiddelde in dezelfde mate veranderen.
Bij 1 mg/ml: 1/0,5 * 0,499 = 0,998 (alternatieve methode: 1,04 mg/ml)
Bij 0,125 mg/ml: 0,125 en 0,130 mg/ml.
Omdat de meetwaarde slechts met ongeveer een factor 0,5/49,5 (~1%) verandert, blijft de standaarddeviatie in de meting vrijwel constant. Aangezien de uitkomst als 1 mg l-vatopolol is toegevoegd, verdubbeld zal de relatieve Sd halveren.
-
Fberekend = 2,74; F7;9; 0,05 = 4,20; H0 niet
te verwerpen. Aanname is dat de beide meetreeksen normaal verdeeld zijn.
-
tberekend = (0,520 - 0,500) / SE = 87; t7; 0,01
= 3,50
H0 verwerpen en H1 aannemen. Het gemiddelde van de alternatieve bepaling wijkt met een foutkans van 1% significant af van de werkelijke waarde.
ongepaarde t-toets: 4,25; t16; 0,01 = 2,92
H0 verwerpen en H1 aannemen. Het gemiddelde
van beide bepaling wijkt met een foutkans van 1%, significant af van elkaar.
-
De herhaalbaarheid van de optische rotatie methode is minder goed dan de
alternatieve methode, maar de alternatieve methode is significant onjuist,terwijl dit niet bewezen kan worden van de optische rotatie-methode. Aangezien de RSD toch nog relatief klein is, zou daarom het best voor
de optische rotatie bepaling gekozen kunnen worden.
-
In het geval van een test op zuiverheid is het van belang, naast de herhaalbaarheid
ook de intermediate precision of de reproduceerbaarheid te kennen. Dit
kan gedaan worden door dezelfde bepaling onder zo verschillend mogelijke
condities uit te voeren (verschillende dagen, verschillende analisten,
verschillende apparaten etc.). Daarnaast is ook de specificiteit van de
bepaling belangrijk, evenals de lineariteit, de range en de minimale detecteerbare
concentratie moet onderzocht zijn.
Vraag 6
-
stap 1
Verschillende de varianties van de tentamenresultaten van de mannen significant van die van de vrouwen? De vraagstelling impliceerd niet dat de scores van de mannen minder spreiding heeft dan die van de vrouwen. Er moet dus 2-zijdig getoetst worden.
H0: s2v = s2m; H1: s2v ¹sm
stap 2
F-toets
stap 3
a = 0,05;
stap 4
1,62 / 1,22 = 1,7
stap 5
F20; 15; 0,05 = 2,76
stap 6
Fberekend < Ftabel
De nulhypothese dat de varianties van de tentamencijfers van de mannen en vrouwen aan elkaar gelijk zijn kan, met een betrouwbaarheid van 95% niet worden verworpen.
-
stap 1
Is het gemiddelde tentamencijfer van de mannen hoger dan dat van de vrouwen? Deze vraag impliceerd dat het de verwachting is dat mannen inderdaad hoger scoren dan vrouwen, er wordt hierom dus 1-zijdig getoetst. (of de vraagstelling "politiek correct" is, is natuurlijk maar zeer de vraag...)
H0: mmkleiner of gelijk mv; H1: mm > mv
stap 2
ongepaarde t-toets
stap 3
a= 0,05; (1-zijdig)
stap 4
tberekend = 1,04
stap 5
t35; 0,05 = 1,69
stap 6
tberekend < ttabel
De nulhypothese dat de gemiddelde tentamencijfers van de mannen en vrouwen kleiner of gelijk aan elkaar zijn kan, met een betrouwbaarheid van 95%, niet worden verworpen.
-
stap 1
Is het gemiddelde tentamencijfer van de studenten in de herkansing hoger?
H0: md kleiner of gelijk aan 0; H1: md > 0
stap 2
gepaarde t-toets
a = 0,05; (1-zijdig)
stap 4
tberekend = 1,94
stap 5
t9; 0,05 = 1,83
stap 6
tberekend > ttabel
De nulhypothese dat het gemiddelde tentamencijfer van de herkansing kleiner of gelijk is aan dat van het reguliere tentamen kan, met een betrouwbaarheid van 95%, worden verworpen. De alternatieve hypothese, dat de herkansing gemiddeld beter is gemaakt, is dus waar.
- Toetsen op uitbuiters kan natuurlijk altijd. Of het zinvol is en of het resultaat iets zegt, is een heel ander punt, is het echt een uitbijter als iemand gewoon niet heeft geleerd???. Op deze discussie zijn zoveel mitsen en maren dat er geen eenduidig antwoord op mogelijk is.
Onthou wel dat je nooit klakkeloos de formule moet invullen, maar dat je nadenkt of het wel terecht is dat je de meting verwerpt.
In de analytische chemie heeft de q-test de functie om meetwaarden die door een toevallige fout in de analyse een te grote afwijking hebben op te kunnen sporen. Als echter aan onafhanelijke monster/proefpersonen gemeten wordt kan men nooit aanwijzen of een eventuele afwijking een meetfout is of dat de proefpersoon/het monster zelf erg afwijkt van de rest en de gemeten waarde dus wel juist is. In het laatste geval is de meetwaarde een "echte" meetwaarde en mag dus niet zomaar weggelaten worden.
Ook hier weer de veronderstelling dat de waarnemingen (cijfers) normaal verdeeld zijn en onafhankelijk van elkaar zijn. Voor de stelling dat deze aannames ook voor tentamenbeoordelingen opgaat, zijn zowel voor- als tegenargumenten op te stellen. Echter, gezien het aantal waarnemingen is zal de normaalverdeling goed worden benadert.
Vraag 7
De berekeningen zijn alleen mogelijk als de waarnemingen (bij benadering) uit een normaal verdeelde populatie komen.
tberekend = 4,16; t9; 0,05 = 2,26
Met een foutkans van 5% kan geconcludeerd worden dat H0 (de aanname dat de gemiddelde van de excreties na 2 uur, gelijk zijn) kan worden verworpen. Malifin heeft een significant andere opnamesnelheid. (Toets ook of deze groter of kleiner is dan Parabruis).
Op eerste gezicht zijn dit waarnemingen van 2 verschillende, onafhankelijke methodes (beide formuleringen zullen niet dezelfde waarneming opleveren) op verschillende monsters (proefpersonen), dus een ongepaarde t-toets (zie ook antwoord opgave 2). Met aanname dat proefpersoon wel effect heeft op waarneming (veel meer dan de methode invloed heeft op de gemiddelde waarneming van de methode), kunnen waarnemingen gezien worden als reeks �afhankelijke� waarnemingen op verschillende monsters.
Oftewel, de interindividuele verschillen van de proefpersonen hebben veel meer invloed op de waarneming dan de intra-individuele verschillen en dan is een gepaarde t-toets mogelijk.
Vergelijk dit met een onderzoek naar het gemiddelde cijfer voor de propadeuse en het doctoraal. Als je wilt zien of propadeusecijfer significant afwijkt van het doctoraal (= verschillende methodes) kan je de cijfers (= waarnemingen) van alle studenten (= verschillende monsters) middelen en dat met elkaar vergelijken. Omdat de cijfers van de studenten onderling sterk verschillen, zal er een een grote interval voor de werkelijke gemiddelde zijn. Daarom kan minder snel een significant verschil worden aangetoond. Door nu het
doctoraalcijfer van elke student te vergelijken met zijn of haar eigen propadeusecijfer is interval veel kleiner geworden. Waarneming nu 'afhankelijk' van het monster (= student).
Vraag 8
- tberekend = 2,59; t9;0,05 = 1,83
Met 5% foutkans is H0 (dat de slaapverlenging van snurkazepam
gelijk is aan temazepam) te verwerpen. De alternatieve hypothese (dat de
slaapverlenging van snurkazepam beter is dan temazepam) wordt dus aangenomen.
Zie ook uitleg bij antwoord opgave 7
-
tberekend = 0,945; t18;0,05 = 2,10
Met 5% foutkans is H0 (dat de slaapverlenging van snurkazepam gelijk is aan
temazepam) niet te verwerpen.
-
Door het paren van de waarneming bij vraag a valt een deel van de variatie in de metingen weg (namelijk een deel van de spreiding die veroorzaakt wordt door de verschillen per proefpersoon). Bij vraag b wordt deze variatie nog steeds meegenomen, hierdoor blijft de totale spreiding groter dan bij a (vergelijk Sd (0,868) bij a met Sp (1,680) bij b). Er valt dus te zien dat met dezelfde waarden het verschil bij a al veel eerder significant is, omdat hier de spreiding veel kleiner is dan bij b.
Farmaceutische Analyse 5e-jaar
|
Hoofdpagina Statistiek
2 Februari 2000
Staf Farmaceutische Analyse 5e-jaar